前端性能优化体系学习之前言
前端性能优化中的难点
- 成体系的性能优化资料严重缺失:
- 缓存请求,服务端响应优化,页面解析与处理,静态资源优化;
- 使用该优化方式的目的,围绕该优化方式对于的指标,优化后的收益等;
- 性能监控预警平台没有开源,需要自己开发:
- 性能优化的重中之重是在于性能监控预警平台;
- 开源的实现需与现有前端基建对接,以及性能平台上包含哪些东西;
- 需要对哪些内容做预警,应该设定怎样的预警策略;
- 实践中存在许多坑,通常不会公开分享:
- 前端指标的制定、采集和上报;
- 异常数据的筛选和处理;
- 性能优化立项沟通:
- 性能优化中的立项是个难点;
- 如何从业务角度去思考性能优化的价值;
- 并说服业务将性能优化提上日程;
- 正推 = 性能线索 -> 性能问题 -> 性能优化方案 -> 性能收益 = ! 反推;
学习的几个重点
- 前端性能优化方法论
- 指标采集上报及优化手段
- Hybrid 下的进阶优化
- 性能优化数据评估及预警
- 一线大厂性能优化体系演进
性能优化体系概览
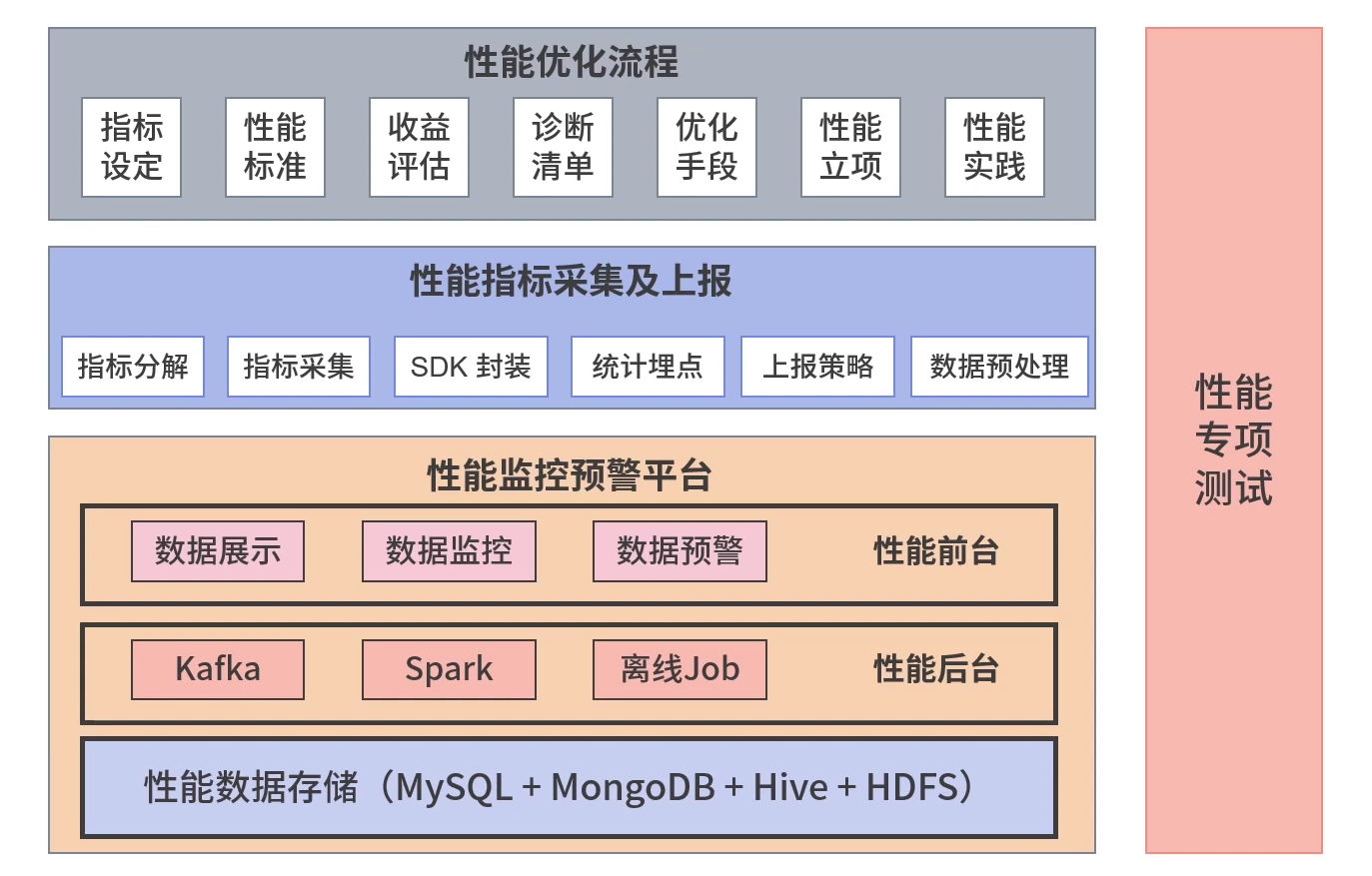
性能优化流程
首先是指标的设定,即我们要选择怎样的性能指标;之后确定性能标准,也就是我们性能优化目标是怎么样的,优化到什么程度合适;
很多时候,为了让产品同学觉得我们是在为产品服务而不是又在造轮子,我们还需要关联产品目标进行收益评估。接下来,把业务代码接入性能监控预警平台,根据性能标准给出诊断清单;诊断出性能问题后,既可以结合性能标准和诊断清单确定相应的优化手段;
之后仍不是性能优化实操,还需要进行性能项目立项,需要赢得产品经理、后端同事支持,是让优化顺利执行下去不可或缺的内容;经过优化之后,产品上线并跟踪进行效果评估,结合场景把这些项目成果以文档或代码的形式沉淀下来。
性能指标采集与上报
主要是将前面提到的性能指标以代码的形式分解落地确保可以采集, 然后在 SDK 封装后集合统计埋点,最后根据实际情况,指定上报策略。
性能监控预警平台
当指标超过某一监控阈值时,性能监控平台会通过邮件或者短信给我们发送预警信息。
- 性能数据处理后台:主要是在性能采集数据上报到性能平台后,对数据进行预处理,数据清洗和数据计算,然后生成前台可视化所需数据。
- 性能可视化展现前台:主要是对核心数据进行可视化展现,对性能数据波动进行监控,对超出阈值的数据给出短信或邮件报警。
为了确保稳定,在上线前一定要做性能专项测试,检查采取的措施和性能优化预期是否一致。
性能关键指标
- 关注什么样的指标
- 可衡量,即可通过代码来度量;
- 关注以用户为中心的关键结果(业务向)和真实体验。
- 关键指标的设定与标准
- 加载:进入页面时,内容的载入过程;
- 交互:用户操作功能页面给出的回复;
视觉稳定性指标
- CLS(cumulative layout shift)即布局偏移量,是指页面一帧切换到另外一帧时,视线中不稳定元素的偏移情况。CLS 比较前沿,目前只依赖于 Google 提供的 Lighthouse 做本地采集,尚无更好的方案。
- 白屏时间,指从输入内容回车(包括刷新,跳转等方式)后到页面开始出现第一个字符的时间。标准时间是 300 ms。
- 导致过长的原因:DNS 查询时间长,建立 TCP 请求太慢,服务器速度慢,客户端下载解析渲染过长,没有做Gzip 压缩,缺乏本地离线化处理等;
- 首屏时间 = 白屏时间 + 渲染时间,从浏览器输入地址栏并回车后,到首页内容渲染完毕的时间,这期间不需要滚动鼠标或下拉页面,否则无效。
- https://gtmetrix.com/,网页性能测试工具;
- 相对于白屏时间,首屏时间更重要,侧重于用户体验;
- 首屏时间 1s 内用户感觉快,超过 2.5 秒则感觉很慢