语法细节
printf 函数:在打印
%时,需要两个连续的%,而不是转义。转换说明:即
%m.pX或%-m.pX,m 为最小字段宽度,指定了最少显示的字符数量,若少于 m 字符,则右对齐,并用空格补齐,多于 m 仍会完全显示,负号则设置左对齐;p 为精度,它取决于转换说明中设置的 X:
%d:指明待显示数字的最少个数,不足则补零;%f:指明小数点后出现的数字个数,默认为 6;%g:指明有效数字的最大数量,与 %f 不同,其不会显示末尾的零,且数值小数点后无值会被省略:
1
2
3
4
5
6
7
8
9
10
11
12
13
14int main(){
float a = 666.66666666;
printf("%.7d\n",(int)a);
printf("%.7f\n",a);
printf("%.7g\n",a);
printf("%.7g\n",(float)(int)a);
return 0;
}
/* 输出
* 0000666
* 666.6666870
* 666.6667
* 666
*/scanf 函数:在处理格式串(例如,
scanf(“%d/%f”, &a);%d/%f 即为格式串)中的转换说明时会跳过每个数的初始位置前的空白字符;而对于普通字符时,采取的动作依赖于该字符是否为空白字符:- 空白字符:当格式串中有一个或多个连续的空白字符,scanf函数会从输入流中重复读取空白字符直到读取到一个非空白字符,并把该字符“放回原处”;
- 其他字符:格式串中出现非空白字符,scanf 函数会将它与下一个输入字符进行比较,匹配则继续处理格式串;否则会异常退出,并把不匹配字符“放回原处”。
0UL/1UL
0UL 表示 无符号长整型 0
1UL 表示 无符号长整型 1
一般的 1 没有后缀,系统默认指定的类型为int,即有符号的整型数。
除此之外还可以将l,u自由组合形成多种后缀(不区分大小写),单独添加也没问题,例如:==2u,3lu,4Lu==。
主要的作用,我只在 keil 编译中遇到过,在宏定义中将1 << 16这类操作,默认的是有符号的,需要将 1 改成 1ul 无符号长整型。
volatile 关键词
首先我们来看volatile在维基百科中的一些简介,有个大概的了解:
在程序设计中,尤其是在C语言、C++、C#和Java语言中,使用volatile关键字声明的变量或对象通常具有与优化、多线程相关的特殊属性。通常,volatile关键字用来阻止(伪)编译器认为的无法“被代码本身”改变的代码(变量/对象)进行优化。如在C语言中,volatile关键字可以用来提醒编译器它后面所定义的变量随时有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从变量地址中读取数据。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。
当用volatile声明变量时,则表示该变量随时可能发生变化,避免因为编译器对代码优化导致读脏数据,例如
1 | static int a; |
一个执行优化的编译器会提示没有代码能修改a的值,并假设它永远都只会是0。因此编译器将用类似==while (true);==的无限循环替换函数体;但是a可能指向一个随时都能被计算机系统其他部分修改的地址,例如CPU的硬件寄存器, 上面的代码永远检测不到这样的修改。如果不使用volatile关键字,编译器将假设当前程序是系统中唯一能改变这个值部分。 为了阻止编译器像上面那样优化代码,需要使用volatile关键字:
1 | static volatile int a; |
这样修改以后循环条件就不会被优化掉,当值改变的时候系统将会检测到。
参考自:Volatile变量
const 关键词
大多数情况下,我们用 const 定义的变量都认为是不可改变的,确实这是准确的,但有些情况下,我们能间接借助指针来修改:
1 |
|
输出结果为:
1 | n: 20 *p:20 |
此外也有情况下是不可修改的:
1 |
|
程序编译正常,但运行时报错Process finished with exit code -1073741819 (0xC0000005);
这是因为 const 全局变量存储在全局存储空间,其值只有可读属性,不能修改;const 局部变量存储在堆栈中,可通过指针修改其值。
代码中的 URL
最近发现一个很有意思的现象,就是在 C 代码中插入一个网站链接,代码不会编译出错:
1 |
|
刚开始,笔者也觉得惊奇,细看也不过如此,https在代码中是一个标签,用于与goto语句跳转到指定代码行,即goto https;,常用于跳出多重循环,国内教材都引导初学者尽量避免使用,因为可能会导致语句上下文不明确,从而使得跳转标签这种语法比较陌生,但有汇编基础,其实感觉goto 和那些 J 指令几乎一样。
//之后的代码就无需多言了,单行注释,编译器会直接跳过后面的内容,直到换行符。
bit field 位域
bit field 是一种节省内存的方式,有些信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位。例如时间日期数据和开关量。位域的类型只能是整型或枚举类型,位域不能是静态数据成员。
时间日期例子,来自C++ Bit Fields | Microsoft Docs:
1 | struct Date { |
由于各个字段的大小都基本固定,所以只需要分配足够的 bits 即可,不过有个小细节,就是unsigned short是 2 个字节 16 位,最后的 nYear 分配的 8 位会溢出,会产生一个新的 16 位的unsigned short,数据由低位开始存储,如下图:
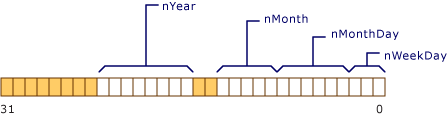
如果结构体中含有一个匿名且长度为 0 的成员,如下:
1 | struct Date { |

因为位域不必然始于一个字节的开始,故不能取位域的地址。指向位域的指针和非 const 引用是不可行的。从位域初始化 const 引用时,将创建一个临时量(其类型是位域的类型),并以该位域的值复制初始化,而引用绑定到该临时量。
如果相邻位域字段的类型不同,长度相同,后面的字段也能紧邻前一个字段存储。
整个结构体仍然满足编译器的对齐原则:整个结构体的总大小为最宽基本类型成员大小(有效对齐值)的整数倍。